

在游戏开发领域,强化学习(Reinforcement Learning,简称RL)逐渐成为主流,DQN(Deep Q-Network,深度Q网络)作为一种先进的强化学习算法,正在逐渐成为开发者和研究者关注的焦点,虽然DQN在许多游戏项目中取得了显著成功,但它的应用仍然面临一些挑战,本文将从DQN的基本原理、实现细节以及实际应用的局限性等方面,探讨DQN的未来发展方向与解决方案。
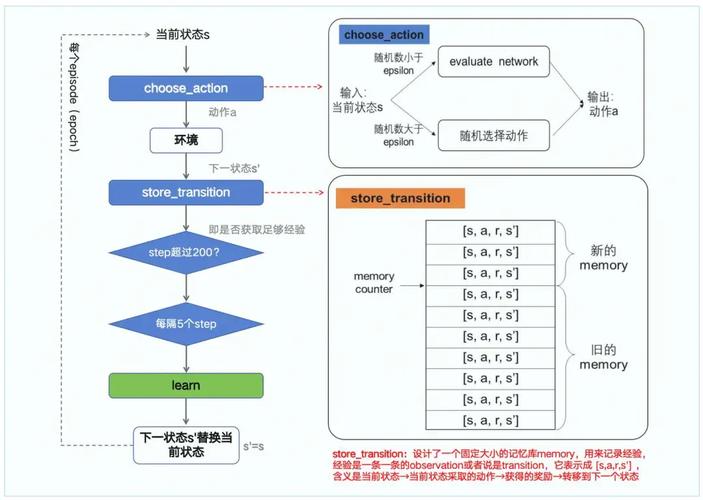
(图片来源网络,侵删)
DQN的基本原理
DQN是一种基于深度学习的强化学习算法,旨在解决复杂的连续控制问题,与传统的Q-learning相比,DQN通过利用深度神经网络(Deep Neural Networks)来近似Q函数,从而在更大的状态空间中找到最优策略。
DQN的核心思想是将Q函数表示为多个层的深度神经网络的输出,每层神经网络对应一个层的Q值估计,通过训练这些神经网络,DQN可以逼近Q函数,从而实现最优控制策略的生成。
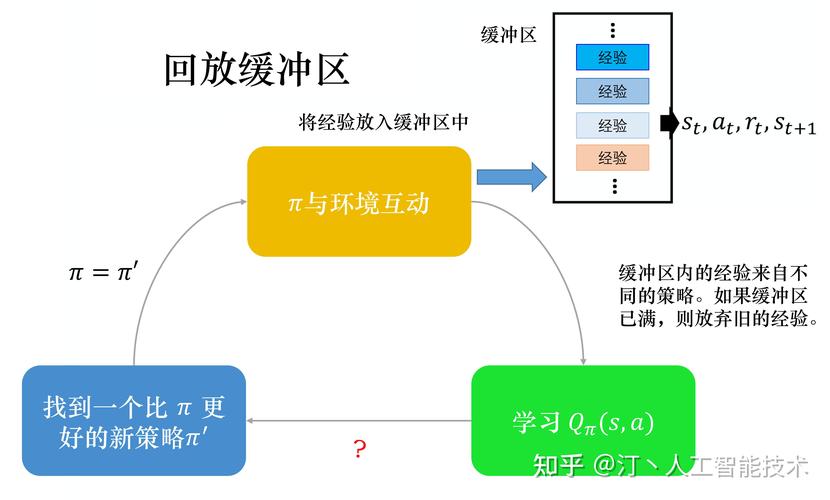
(图片来源网络,侵删)
与传统的Q-learning相比,DQN有几个显著的不同:
- Q网络的状态空间:传统的Q-learning通常在有限的状态空间中进行,而DQN能够处理无限或连续的状态空间。
- 层化结构:DQN通过多层的深度神经网络来近似Q函数,能够捕捉到复杂的状态-动作空间关系。
- 目标网络:为了减少网络梯度消失的问题,DQN通常使用目标网络来近似Q函数的目标值,而不需要实时更新目标函数。
DQN的基本实现步骤
DQN的实现流程大致分为以下几个步骤:
- 数据准备:收集游戏中的状态数据(例如游戏环境中的回合、分数等),定义动作空间(如移动、攻击等)。
- 模型架构设计:设计一个Q网络,其输入是状态或(状态,动作)对,输出是Q值。
- 训练过程:
- 随机初始化:对神经网络进行随机初始化。
- 数据集构建:构建训练数据集,通常包括多个训练样本,每个样本由状态和动作对组成。
- 训练循环:通过反向传播(Backpropagation)计算梯度,更新网络参数。
- 目标更新:使用目标网络更新Q函数的目标值,以减少梯度消失的问题。
- 评估与优化:在训练完成后,通过测试数据集评估模型性能,并根据结果调整模型参数。
DQN的优缺点
尽管DQN在许多游戏项目中取得了显著成功,但其在实际应用中的局限性也逐渐显现:
- 训练复杂性:DQN的训练过程相对复杂,对开发者提出了更高的要求。
- 模型依赖性:DQN的性能依赖于模型的质量,如果模型设计不合理,可能导致性能下降。
- 计算资源需求:DQN的训练需要大量的计算资源,尤其是当状态空间较大时,计算成本会显著增加。
DQN的未来发展方向
尽管DQN在许多领域取得了突破,但其在某些场景中的应用仍然面临一些挑战,DQN的改进方向可能包括以下几个方面:
- 模型优化:进一步优化DQN的模型架构,使其更高效、更稳定。
- 多任务学习:扩展DQN到多任务学习场景,同时在多个目标上优化Q函数。
- 实时性提升:通过技术优化,如并行计算、模型压缩等,提升DQN的实时性。
- 高精度控制:进一步提升DQN的控制精度,使其在复杂场景中表现更佳。
DQN作为一种先进的强化学习算法,正在逐步成为游戏开发中的主流工具,其在实际应用中的局限性和挑战仍然需要进一步解决,随着计算技术的进步和模型优化的进一步深入,DQN有望在更多领域中发挥其应有的作用。
如果你对DQN感兴趣,或者正在尝试开发一个游戏,建议你参考一些优秀的DQN实现,如OpenAI的PPO(Proximal Policy Optimization)等,这些算法都是DQN的改进版,结合了深度学习和强化学习的优势。



